pip install git+"https://github.com/nliulab/ShapleyVIC#egg=ShapleyVIC&subdirectory=python"ShapleyVIC: Shapley Variable Importance Cloud for Interpretable Machine Learning
ShapleyVIC Introduction
Variable importance assessment is important for interpreting machine learning models. Current practice in interpretable machine learning applications focuses on explaining the final models that optimize predictive performance. However, this does not fully address practical needs, where researchers are willing to consider models that are “good enough” but are easier to understand or implement. Shapley variable importance cloud (ShapleyVIC) fills this gap by extending current method to a set of “good models” for comprehensive and robust assessments. Building on a common theoretical basis (i.e., Shapley values for variable importance), ShapleyVIC seamlessly complements the widely adopted SHAP assessments of a single final model to avoid biased inference. Please visit GitHub page for source code.
Usage
As detailed in Chapter 3 ShapleyVIC analysis of variable importance consists of 3 general steps:
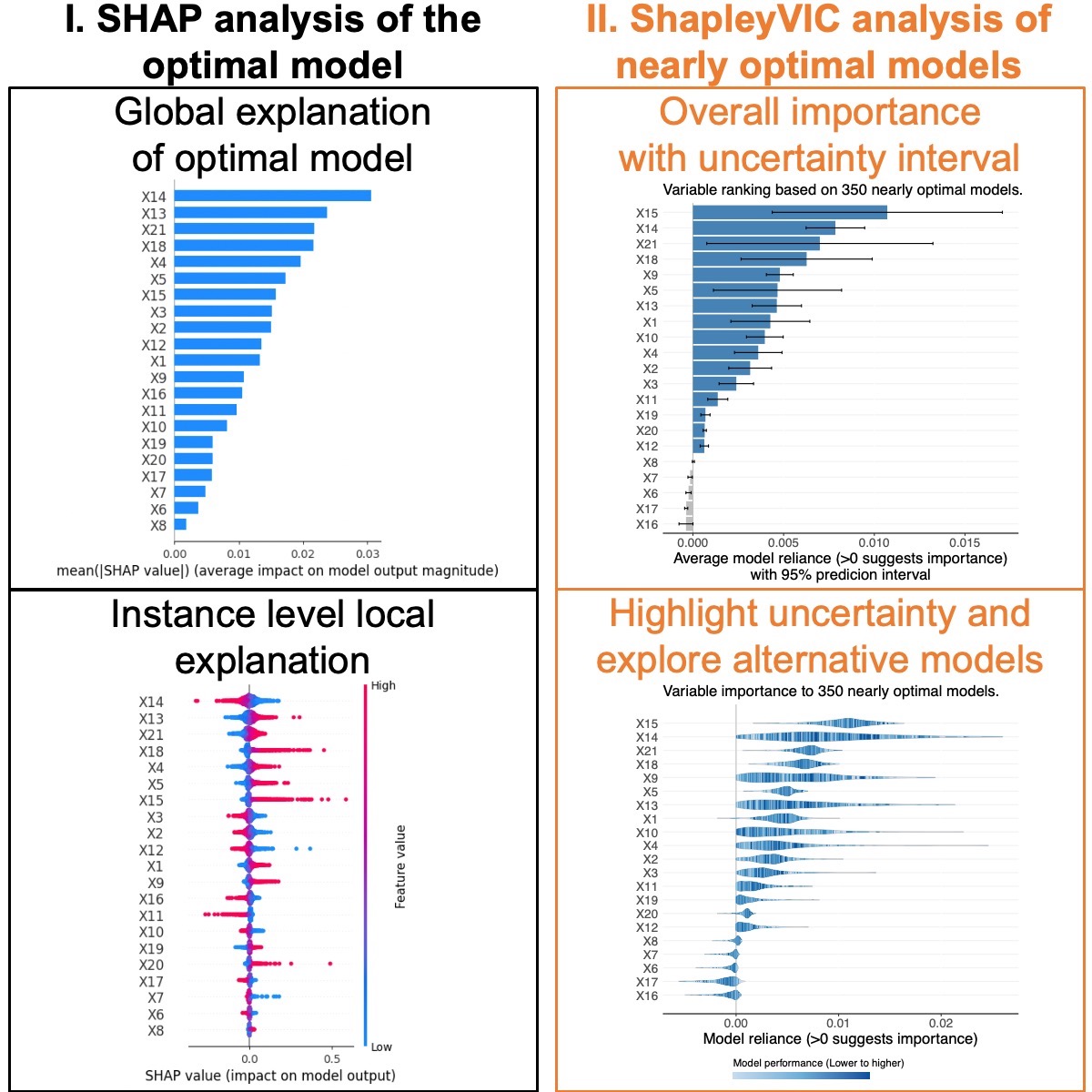
- Training an optimal prediction model (e.g., a logistic regression model).
- Generating a reasonable number of (e.g., 350) nearly optimal models of the same model class (e.g., logistic regression).
- Evaluate Shapley-based variable importance from each nearly optimal model and pool information for inference.
Chapter 3 demonstrates ShapleyVIC application for binary outcomes, and Chapter 6 and Chapter 7 provide additional examples for applications for ordinal and continuous outcomes, respectively.
ShapleyVIC does not require variable centering or standardization, but requires some data checking and pre-processing for stable and smooth processing, which we summarize in Chapter 2.
The ShapleyVIC-based variable ranking can also be used with the AutoScore framework to develop clinical risk scores for interpretable risk prediction, which we demonstrate in Chapter 4 and Chapter 5.
Installation
The ShapleyVIC framework is now implemented using a Python library that trains the optimal model, generates nearly optimal models and evaluate Shapley-based variable importance from such models, and an R package that pools information across models to generate summary statistics and visualizations for inference.
Python library
- Required: Python version 3.6 or higher.
- Recommended: latest stable release of Python 3.9 or 3.10.
- Required: latest version of git.
Execute the following command in Terminal/Command Prompt to install the Python library from GitHub:
- Linux/macOS:
- Windows:
python.exe -m pip install git+"https://github.com/nliulab/ShapleyVIC#egg=ShapleyVIC&subdirectory=python"
Note
- ShapleyVIC uses a modified version of the SAGE library (version 0.0.4b1), which avoids occasional stack overflow problems on Windows but does not affect variable importance evaluation.
R package
Execute the following command in R/RStudio to install the R package from GitHub:
if (!require("devtools", quietly = TRUE)) install.packages("devtools")
devtools::install_github("nliulab/ShapleyVIC/r")Citation
Core paper
- Ning Y, Ong ME, Chakraborty B, Goldstein BA, Ting DS, Vaughan R, Liu N. Shapley variable importance cloud for interpretable machine learning. Patterns 2022; 3: 100452.
Method extension
- Ning Y, Li S, Ong ME, Xie F, Chakraborty B, Ting DS, Liu N. A novel interpretable machine learning system to generate clinical risk scores: An application for predicting early mortality or unplanned readmission in a retrospective cohort study. PLOS Digit Health 2022; 1(6): e0000062.
Clinical applications
- Deng X, Ning Y, Saffari SE, Xiao B, Niu C, Ng SYE, Chia N, Choi X, Heng DL, Tan YJ, Ng E, Xu Z, Tay KY, Au WL, Ng A, Tan EK, Liu N, and Tan LCS (2023). Identifying clinical features and blood biomarkers associated with mild cognitive impairment in Parkinson’s Disease using machine learning. European Journal of Neurology, 00:1–9.
Contact
- Yilin Ning (Email: yilin.ning@duke-nus.edu.sg)
- Nan Liu (Email: liu.nan@duke-nus.edu.sg)